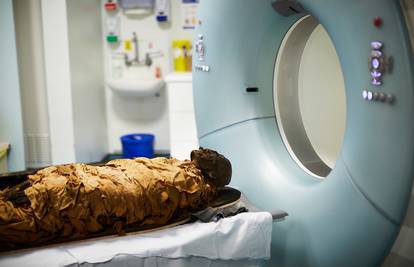
Engleski stučnjaci napravili su detaljna mjerenja glasovnog trakta svećenika umrlog prije više od 3000 godina te na 3D printeru izradili umjetnu verziju kako bi mogli sintetizirati jedan jezivi ton
'PROGOVORIO' U MUZEJU
Poslušajte kako zvuči mumija iz Egipta nakon 3000 godina







Mumija je 'proizvela' zvuk prvi put u zadnjih 3000 godina. Naime, mumificirani svećenik proizveo je zvuk u muzeju Leeds City Museum gdje se trenutno nalazi.
Britanski istraživači reproducirali su ton koji je proizveo svećenik znani kao Nesajmun, pomoću vokalnog trakta otisnutog na 3D printeru, objavljeno je u časopisu Nature.
We've been keeping something secret. Something wonderful. In 2016, a team took our Egyptian mummy, the priest Nesyamun,...
Posted by Leeds Museums and Galleries on Thursday, January 23, 2020
Glas na početku zvuči kao glasanje koze, ali ako ga poslušate više puta počinje zvučati kao ton između razvučenog 'e' i 'a'.
Tim stručnjaka iz Engleske analizirao je grkljan i grlo svećenika te su uzeli detaljne mjere, koje nečiji glas čine jedinstvenim. Da bi im ovo uspjelo tkivo Nesajmunovog glasovnog trakta moralo je biti praktički netaknuto.
Na temelju tih mjerenja izradili su glasovni trakt na 3D printeru koji je uz pomoć umjetnog grkljana proizveo ovaj jezivi zvuk.
Na temelju otkrića, tim u Engleskoj ispisao je 3D vokalni trakt, koji ukoliko se koristi s umjetnim grkljanom, stvara zvuk za kojeg se boje da će ih proganjati danima.
- Ova inovativna interdisciplinarna suradnja pružila nam je jedinstvenu priliku da čujemo zvuk nekoga mrtvog zahvaljujući očuvanju mekih tkiva u kombinaciji s novim dostignućima u tehnologiji - rekao je Joan Fletcher, profesor u odjelu za arheologiju u Yorku.
Vokalizacija je prema stručnjacima bila dio svakodnevnih rituala u antičkom Egiptu, iako nije bila precizna, uključivala je govor i pjevanje. Ovo otkriće ima posljedice za zdravstvo i muzejski prikaz, ali i potvrđuje vjerovanje da "izgovarati ime mrtvih, znači ponovo ih oživjeti".
Naravno, ovaj jezivi ton teško da je precizno oponašanje stvarnog glasa svećenika jer je njegov jezik kroz tisuće godina također izgubio velik dio mase. Koautor studije David Howard kaže da je ovakav glas vjerno oponašanje glasovnog trakta u stanju kakvom je. I ovakav model nije dovoljan da bi uopće mogli sintetizirati cijele riječi.
Sve što je bitno, na dohvat ruke
Skini aplikaciju za najbolje iskustvo portala. Čitaj, komentiraj i budi uvijek u toku s najnovijim vijestima.


Odaberi temu koju želiš pratiti
Primaj sve nove vijesti o temi i budi u tijeku